Title here
Summary here
The Green Metrics Tool has the capability to compare two or more measurements.
Comparing measurements is intended to give an insight into the order of magnitude
of energy the running software is consuming under certain circumstances.
Ultimately, these cases for comparing measurements should span the entire
lifecycle of software development and use.
Comparison is currently possible for measurements that are:
The tool will let you know if you try to compare measurements that can’t be compared.
To trigger a comparison in the frontend just tick the boxes of the runs you wish to compare and click the Compare Runs button.
Example of a comparison display
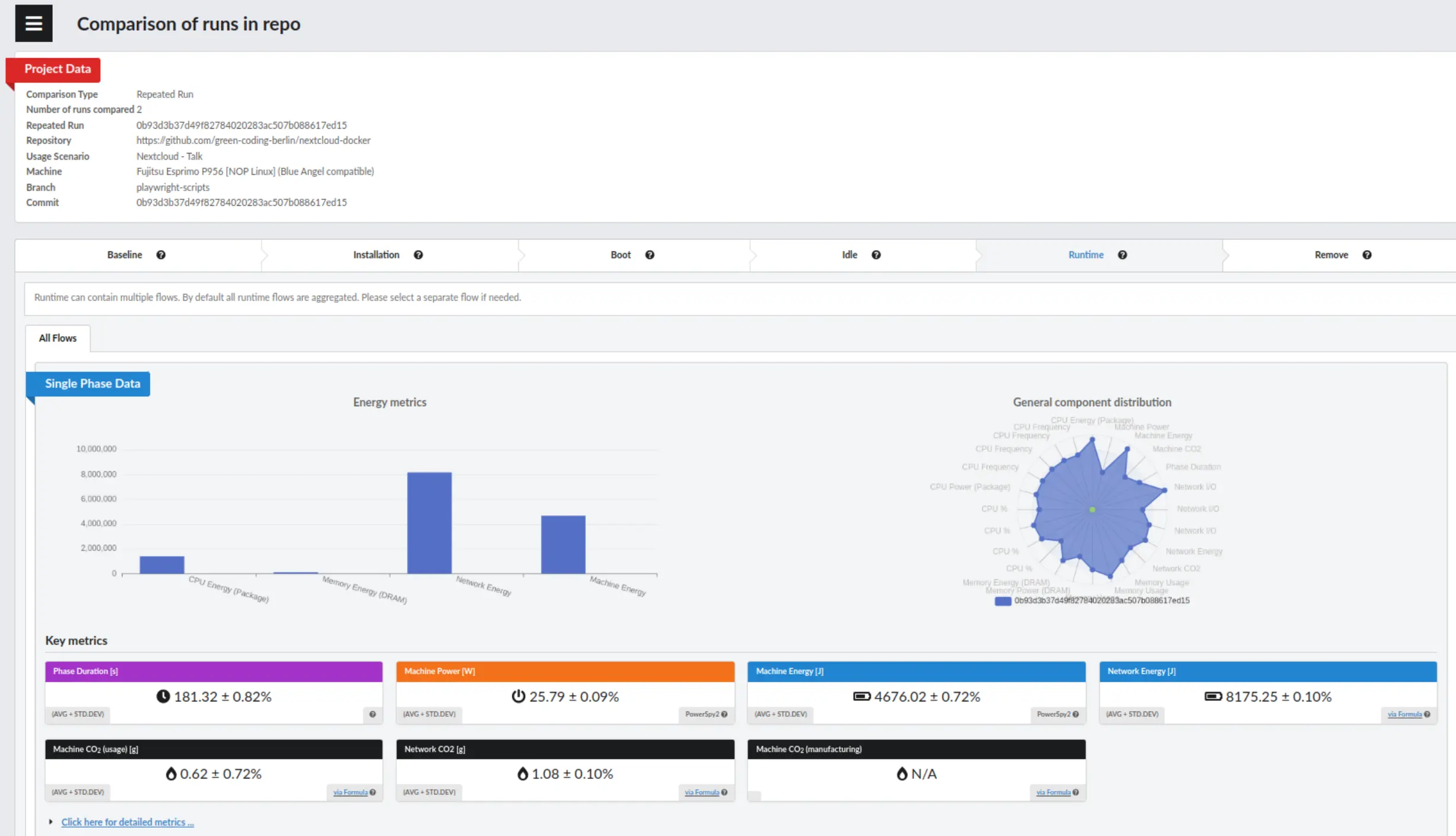
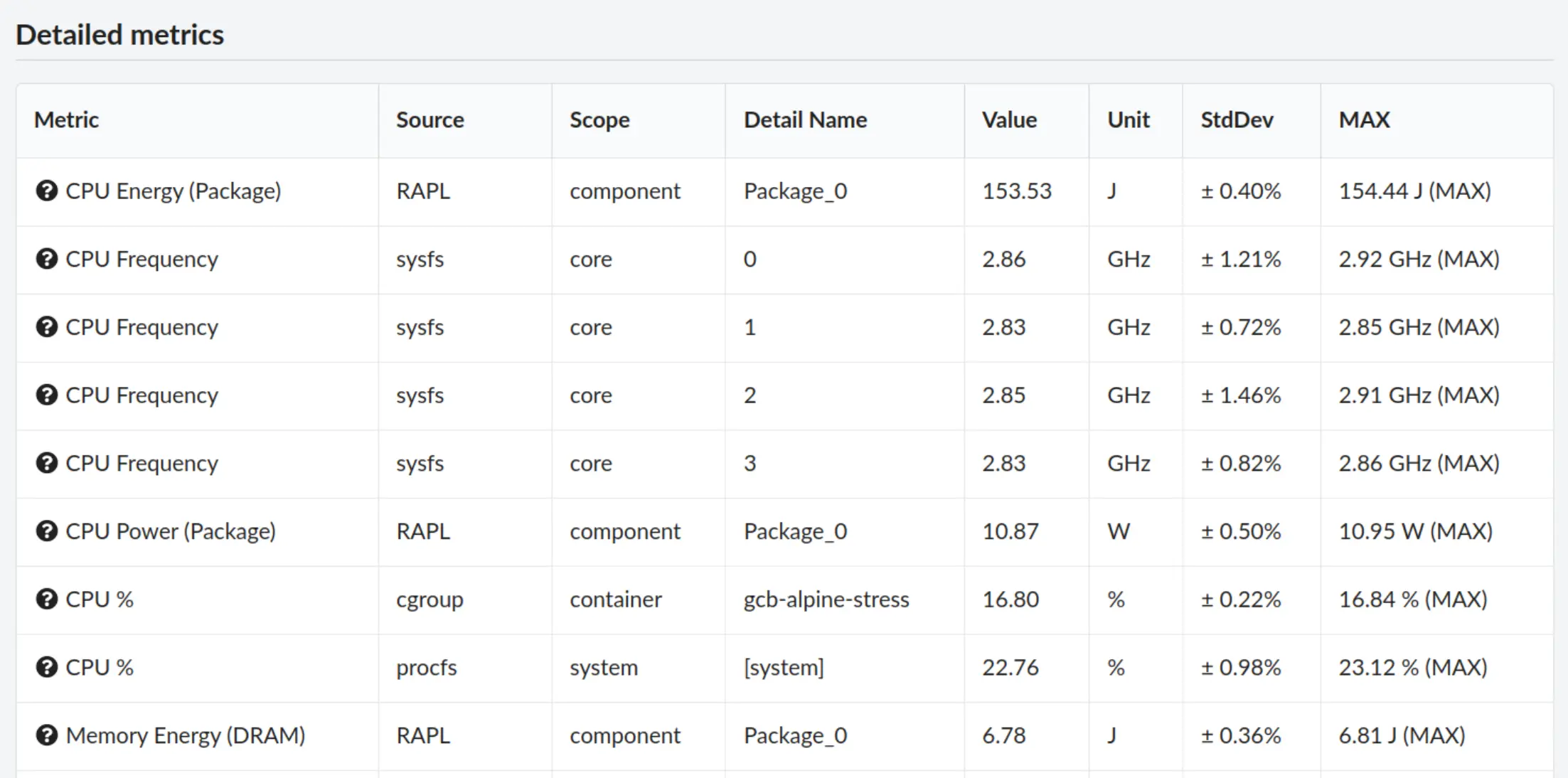
When comparing measurements, you will see the standard deviance on the key metrics
and in a column under the detailed metrics.
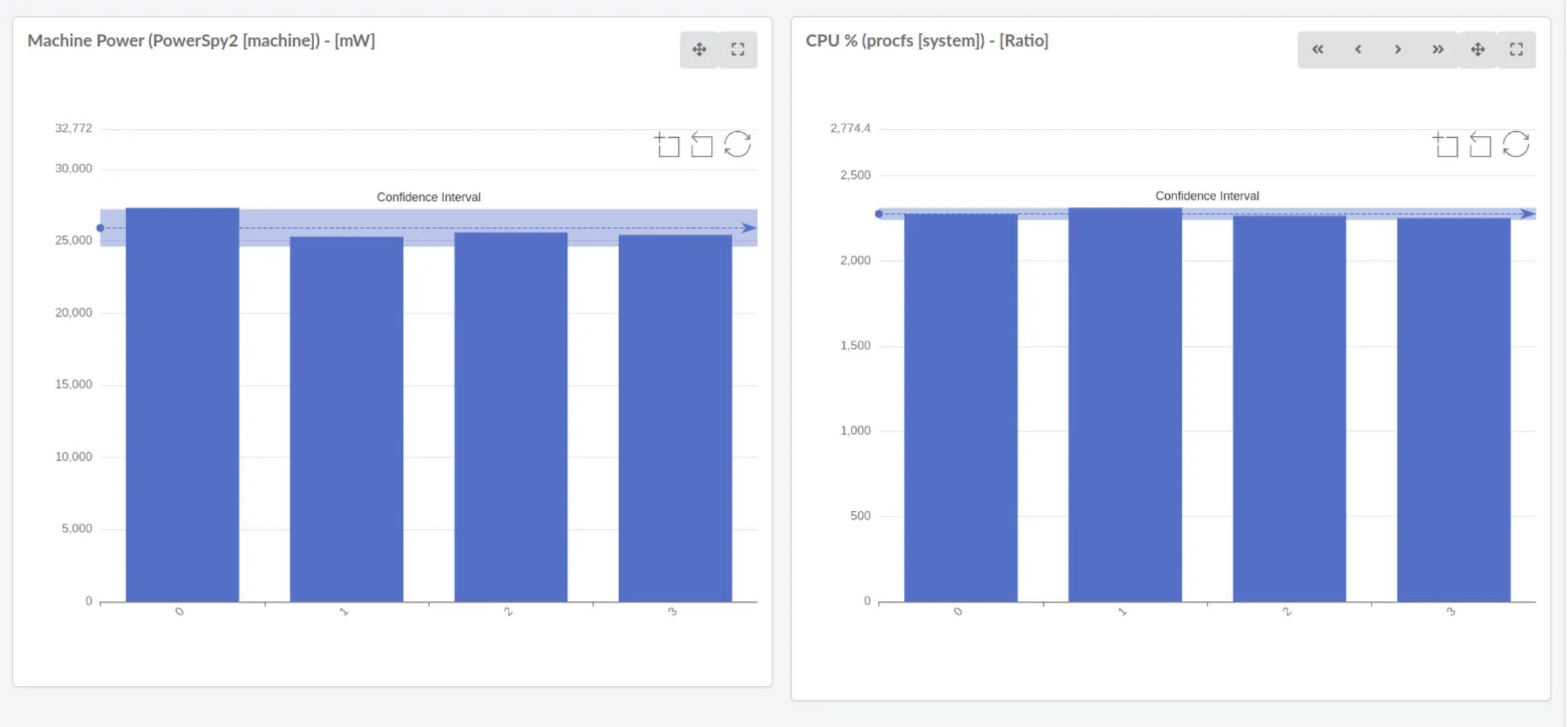
Graphs will also include the confidence interval.
Comparing measurements should help raise awareness of software energy use over time.
In some instances the GMT will not allow certain comparisons. For instance when you compare different machines and also different repositories. A comparion like this sounds unreasonable for the GMT as machine and comparing should not be changed simultaneusly.
But still there might be instances when you want to force a certain comparison type. For instance when the repository is basically the same as the old one, just has been renamed. GMT does not understand repository renaming currently.
In that or similar cases you can override the default comparison mode auto detection and use the Export Mode.
Navigate to Settings and toggle Expert compare mode.
A new box will appear when comparing settings where you can force a mode. For instance treating runs from different repositories and branches with different commits, which however have run on the same machine as a Machine comparison will effectively compare them as being just repeated runs on the same machine.
Your runs must in any case have one common demoniator, that has at max two values. For instance:
When running a comparison between different commits, different machines etc. the GMT will also compute a T-test for the two samples.
It will calculate the T-test for the means of two independent samples of scores assuming even independent variances. (Some might know this test also as Welch’s t-test or Welch test)
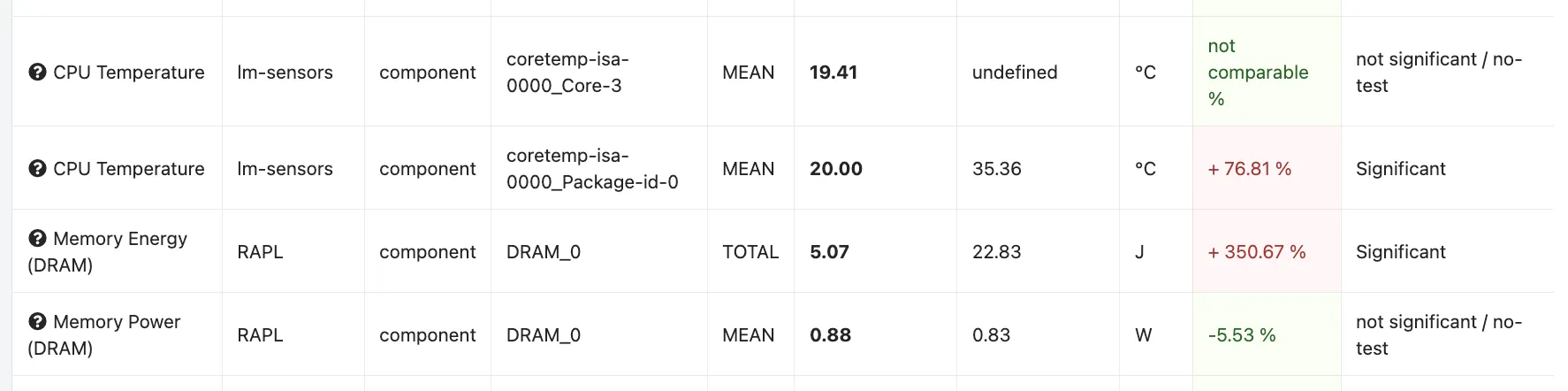
If the p-value is lower than 0.05 GMT will show the result as significant.
GMT will provide the p-value directly in the API output of the comparison. In the frontend it will be shown with a green / red indicator for the significance. Green meaning significant. Or it will tell you if a comparison could not be made in case there where too many missing values or the metric was not present in all runs.
When running a comparison of repeated runs with no diffentiating criteria like different commits, repos etc. the GMT will run a 1-sample T-test. Effectivly answering the question: “Did the last run in the set of repeated runs have a siginificant variation to the ones before”.
This question is very typical as you will have a set of a couple of runs once measured. Then you come back to your code and just re-measure out. The value is now different and you want to tell if it is significantly different.
If the p-value is lower than 0.05 GMT will show the result as significant.
GMT will provide the p-value directly in the API output of the comparison. In the frontend it will be shown with a green / red indicator for the significance. Green meaning significant. Or it will tell you if a comparison could not be made in case there where too many missing values or the metric was not present in all runs.